[데이터베이스] SELECT - 1
- Graphic Syntax Diagram의 기본 구조 설명 (여기 참고)
>주경로와 곁가지
주경로: 여러 키워드 중 반드시 하나는 필요한 경우
곁가지: 키워드나 파라미터가 옵션
>Multipart Diagrams
신택스 다이어그램이 너무 길어 한 줄로 표현되지 않을 때 여러 줄로 나누어 표현한 것
왼쪽부터 시작해 오른쪽 끝에 다다르면 다음 줄 왼쪽부터 읽으면 됨
>도형
사각형: 키워드 혹은 명령어 (대문자로 표시)
타원형: 파라미터 (A-1 확인)
원형: punctuation(쉼표, 마침표와 같은 구두점), operator(연산자), delimiter(구분자 , ; : $), terminator(종결자?)
>Syntax Loop ????????????????????
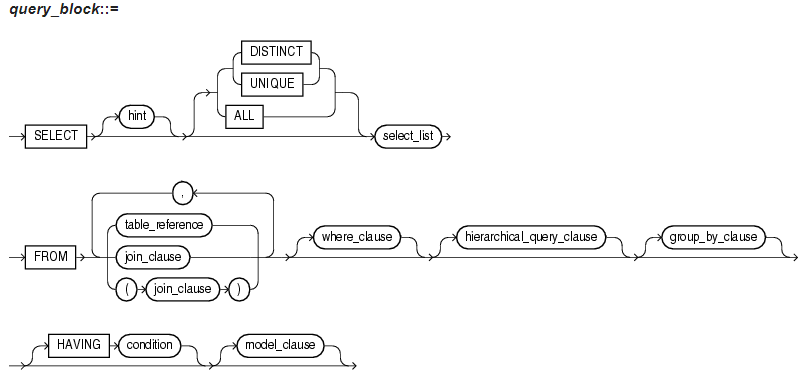
----1번 라인-------------------------------------------------------------------------------------------------------------------
- SELECT
테이블에 있는 데이터를 조회하는 명령어
- hint
SQL 튜닝의 핵심부분으로 일종의 지시구문
Optimizer에 의존하여 나온 실행 계획보다 훨씬 효율적인 실행계획을 사용자가 구사할 수 있다.
Optimizer의 실행 계획을 개발자가 원하는 대로 바꿀 수 있게 해준다.
테이블이나 인덱스의 잘못된 실행 계획을 개발자가 직접 바꿀 수 있도록 도와주는 것
형식: /*+ 힌트내용 */
cf) Optimizer, 튜닝
Optimizer: SQL을 가장 빠르고 효율적으로 수행할 최적(최저비용)의 처리경로를 생성해 주는 DBMS 내부의 핵심엔진
튜닝: SQL 문을 최적화하여 빠른 시간내에 원하는 결과값을 얻기 위한 작업
- DISTINCT
특정 열 내 중복된 데이터를 필터링해서 조회
ex) SELECT DISTINCT JOB FROM EMP;
- UNIQUE
기본 키에 참여하고 있지 않은 특정 열에 중복 값이 입력되지 않도록 하는 키워드
- DISTINCT와 UNIQUE의 차이점
일단 둘은 동의어
DISTINCT가 표준 SQL키워드, UNIQUE는 오래된 syntax(문법)
DISTINCT는 주로 만들어진 데이터를 읽을 때, UNIQUE는 데이터를 주입할 때 사용
- ALL
특정 열 내 모든 행을 리턴하는 키워드
- select_list
조회하고싶은 컬럼(=attribute, feature, field, variable = 열)
----2번 라인-------------------------------------------------------------------------------------------------------------------
- FROM (키워드)
FROM절은 조작할 테이블 소스를 불러오는 키워드(?)
- table_reference (parameter: table)
조작할 테이블
- join_clause (parameter: table) ?????????????????????
두개 이상의 테이블에 대해서 결합하여 나타낼 때
종류: 이너 조인, 아우터 조인, 크로스 조인, 셀프 조인
- where_clause (parameter: condition)
일종의 조건문...where 뒤의 조건문을 만족하는 row를 출력하겠다는 뜻
- hierachical_query_clause (계층구조 쿼리, 여기 참고)
데이터를 수직적인 계층구조로 리턴할 때 사용
구조: START WITH, CONNECT BY 키워드로 이뤄짐
ex) SELECT LEVEL, empno, ename, mgr
FROM emp
START WITH job = 'PRESIDENT'
CONNECT BY PRIOR empno = mgr;
- group_by_clause
데이터들을 원하는 그룹으로 나눌 수 있다.
----3번 라인-------------------------------------------------------------------------------------------------------------------
- HAVING-condition (키워드, 파라미터(조건))
집계함수를 가지고 조건비교를 할 때 사용
WHERE 절에는 집계함수를 사용할 수 없다... 그럴때 HAVING절 사용
(cf. 집계함수
입력이 여러개의 로우이고, 출력이 하나인 결과인 것
ex) count, sum, avg, max, mim ...)
- model_clause (파라미터: 조건)
스프레드시트와 같이 계산식을 사용하여 그 결과를 깔끔한 가상의 셀 형태로 볼 수 있다.